新年あけましておめでとうございます。久々の投稿になります(半年ぶり。。)
googleアナリティクスもなんか仕様変更したのか、昔の設定ではサイトのアクセス数などが確認できなくなっていてもともと弱小だったこのサイトなんかもはやだれ一人見ていないのではないかと感じますが、今年からまたちょくちょく更新していこうかと思っています。どうぞよろしくお願いいたします。
*****
昨年、AIロボット「AIパワー君」を作成したのですが、結構苦労したので備忘録としてまとめておこうと思います。
出来上がりはこんな感じです。↓
ロボットの機能は下記の通り。
・chatgptと連携させて会話ができる
・音声での操作
・前後と左右旋回歩行が可能
・カメラを搭載しブラウザから歩行操作可能
・アナログコントローラーで各部関節のみの操作も可能
過去に作成した「パワー君」をベースとしています。↓

この記事が、会話できるAIロボットを作りたいと思っている方の参考になれば幸いです。
ロボットの構成
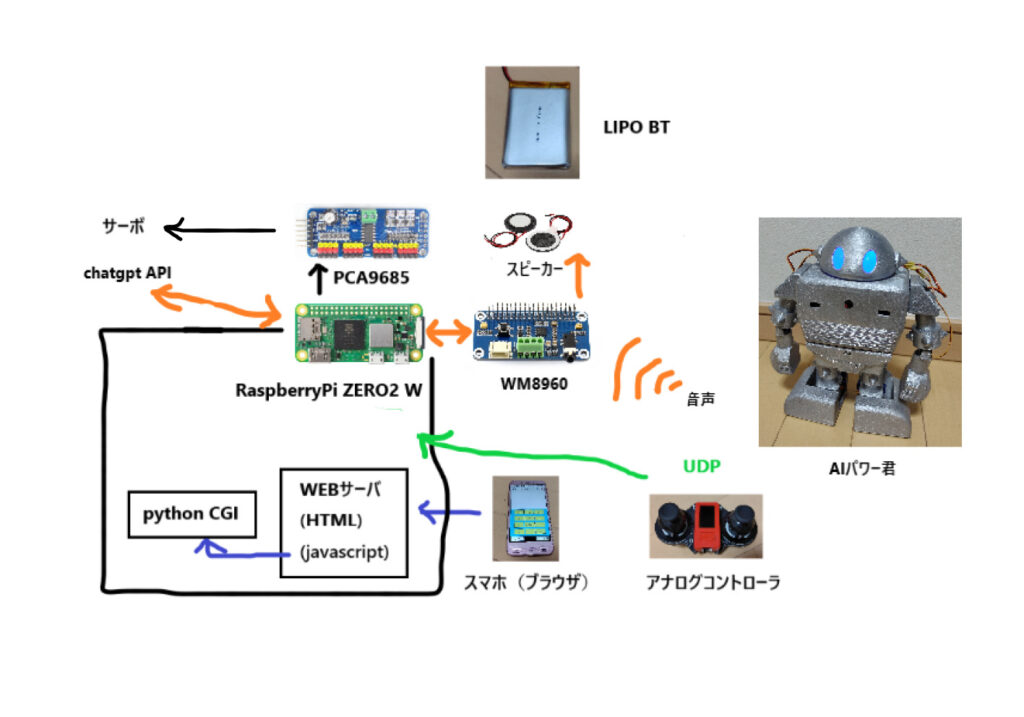
ハード
・Raspberrypi ZERO2W
・WM8960 Audio HAT
・スピーカー × 2個
・PCA9685
・サーボモーター × 12個(SG90 × 10, ミニデジタルサーボ2g(正式名称不明)× 4)
・Lipo BT 2000mAh 放電レート2C × 1個
ソフト
プログラムはpythonで書いてます。
ブラウザからの操作についてはhtml,css,js,python cgiで書いています。
作成過程
印刷、塗装
外装は一部変更(micとスピーカーの穴を追加)したパワー君をベースとして印刷し、ホビー用スプレーのメタリックシルバー色で塗装しました。
メタリックのせいかラメが入っていて、スプレー時に空中に舞いまくるので要注意でした。
組立て
部品格納
RaspberryPi ZEROW2にWM8960を取り付けてスピーカーを接続。
WM8960は接続コネクタのピンが長かったの短くしました。(筐体に収まらないため)
配線
サーボモーターを取りつけて基板との配線。
接続のコネクタは場所を取るので全て取り外して直付けしました。
プログラム
コントローラー側、ロボット側のプログラムについては冒頭に張り付けましたURL(パワー君)のものとほぼ同一です。
今回はAIロボットということで、chatgptを利用し会話できるプログラムを追加しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 |
import pyaudio import struct import math import audioop import wave import time import os import io from google.cloud import speech import openai from google.cloud import texttospeech from gtts import gTTS import pygame.mixer import Adafruit_PCA9685 import threading import RPi.GPIO as GPIO led = 0 pwm = Adafruit_PCA9685.PCA9685() pwm.set_pwm_freq(60) a = 350 b = 320 c = 400 d = 360 e = 400 z = 360 g = 370 h = 330 i = 340 j = 430 k = 380 l = 390 time.sleep(1) pwm.set_pwm(0, 0, a) pwm.set_pwm(1, 0, b) pwm.set_pwm(2, 0, c) pwm.set_pwm(3, 0, d) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) pwm.set_pwm(7, 0, h) pwm.set_pwm(8, 0, i) pwm.set_pwm(9, 0, j) pwm.set_pwm(10, 0, k) pwm.set_pwm(11, 0, l) time.sleep(0.5) while led <= 4095: pwm.set_pwm(12, 0, led) pwm.set_pwm(13, 0, led) led = led + 15 #bb = bb + 15 time.sleep(0.01) led = led - 15 print("off") time.sleep(2) while led >= 0: pwm.set_pwm(12, 0, led) pwm.set_pwm(13, 0, led) led = led - 15 #bb = bb - 15 time.sleep(0.01) led = led + 15 time.sleep(0.1) pygame.mixer.init() openai.api_key = "key" os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '------.json' # Instantiates a client client = speech.SpeechClient() ### 音声データを指定 speech_file = 'output.wav' chunk = 1024 FORMAT = pyaudio.paInt16 CHANNELS = 1 RATE = 44100 INPUT_DEVICE_INDEX = 0 THRESHOLD = 3000 #700 SILENCE_LIMIT = 3 RECORD_SECONDS = 5 WAVE_OUTPUT_FILENAME = "output.wav" p = pyaudio.PyAudio() def get_rms(block): """ Returns the root mean square of the audio block. """ return audioop.rms(block, 2) def get_audio_input_device(p, input_device_index, channels=1, rate=44100, frames_per_buffer=1024): stream = p.open(format=pyaudio.paInt16, channels=channels, rate=rate, input=True, input_device_index=input_device_index, frames_per_buffer=frames_per_buffer) return stream def ask_gpt(text): response = openai.Completion.create( engine="davinci", # 使用する言語モデルを指定する prompt=text, max_tokens=1024, # 応答の長さを指定する n=1, # 応答の候補数を指定する stop=None, # 応答の終了条件を指定する ) return response.choices[0].text.strip() # text to speech関数(引数:変換テキスト、対応言語、出力ファイル名) def text_to_speech(text, language, name): # gTTSインスタンスの作成 text2speech = gTTS(text, # 音声変換するテキスト lang=language, # 対応言語(ja:日本語) ) # 音声変換したデータをファイルに保存 text2speech.save(name + ".mp3") return True stream = get_audio_input_device(p, INPUT_DEVICE_INDEX, CHANNELS, RATE, chunk) is_recording = False silence_counter = 0 frames = [] #frames = [bytes(frame) for frame in frames] type = "nane" t_end = time.time() t_time = 3 text = "" def recieve(): global led while(led <= 4095): pwm.set_pwm(12, 0, led) pwm.set_pwm(13, 0, led) led = led + 15 time.sleep(0.01) led = led - 15 def recieve2(): global led while(led >= 0): pwm.set_pwm(12, 0, led) pwm.set_pwm(13, 0, led) led = led - 15 time.sleep(0.01) led = led + 15 def power(): global a, b, c, d, e, z, g, h, i, j, k, l, text name = "gTTS_Text2Speech" text = "こんにちは" language = "ja" text_to_speech(text, language, name) pygame.mixer.music.load("gTTS_Text2Speech.mp3") pygame.mixer.music.play(0) #while True: # if(pygame.mixer.music.get_busy()!=True): # break # time.sleep(0.2) # pygame.mixer.music.stop() #time.sleep(0.5) #text = "" pwm.set_pwm(12, 0, 0) pwm.set_pwm(13, 0, 0) while(e <= 480): pwm.set_pwm(4, 0, e) e = e + 2 time.sleep(0.005) time.sleep(1) while(z <= 580): pwm.set_pwm(5, 0, z) z = z + 2 time.sleep(0.005) time.sleep(0.5) while(j <= 520): pwm.set_pwm(9, 0, j) j = j + 2 time.sleep(0.005) time.sleep(3) pwm.set_pwm(12, 0, 4095) pwm.set_pwm(13, 0, 4095) pwm.set_pwm(11, 0, 280) name = "gTTS_Text2Speech" text = "パワー" language = "ja" text_to_speech(text, language, name) pygame.mixer.music.load("gTTS_Text2Speech.mp3") pygame.mixer.music.play(0) #while True: # if(pygame.mixer.music.get_busy()!=True): # break # time.sleep(0.2) # pygame.mixer.music.stop() time.sleep(3) e = 400 z = 360 h = 330 j = 430 #GPIO.output(LED_2,GPIO.LOW) pwm.set_pwm(12, 0, 0) pwm.set_pwm(13, 0, 0) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(7, 0, h) pwm.set_pwm(9, 0, j) pwm.set_pwm(11, 0, l) text = "" def fw(): global a, b, c, d, e, z, g, h, i, j, k, l, text, led name = "gTTS_Text2Speech" text = "はい" language = "ja" text_to_speech(text, language, name) pygame.mixer.music.load("gTTS_Text2Speech.mp3") pygame.mixer.music.play(0) while(led <= 4095): pwm.set_pwm(12, 0, led) pwm.set_pwm(13, 0, led) led = led + 15 time.sleep(0.01) led = led - 15 while True: if(pygame.mixer.music.get_busy()!=True): break time.sleep(0.2) pygame.mixer.music.stop() time.sleep(1) text = "" while(d >= 305): pwm.set_pwm(1, 0, b) pwm.set_pwm(3, 0, d) d = d - 2 b = b - 2 time.sleep(0.005) #time.sleep(3) while(c <= 470): pwm.set_pwm(2, 0, c) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) c = c + 2 z = z - 2 g = g - 2 e = e - 2 time.sleep(0.005) #time.sleep(3) while(b <= 320): pwm.set_pwm(1, 0, b) pwm.set_pwm(3, 0, d) d = d + 2 b = b + 2 time.sleep(0.005) #time.sleep(3) while(c >= 400): pwm.set_pwm(2, 0, c) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) c = c - 2 z = z + 2 g = g + 2 e = e + 2 time.sleep(0.005) #time.sleep(3) while(b <= 380): pwm.set_pwm(1, 0, b) pwm.set_pwm(3, 0, d) b = b + 2 d = d + 2 time.sleep(0.005) #time.sleep(3) while(a >= 280): pwm.set_pwm(0, 0, a) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) a = a - 2 z = z + 2 g = g + 2 e = e + 2 time.sleep(0.005) #time.sleep(3) while(b >= 320): pwm.set_pwm(1, 0, b) pwm.set_pwm(3, 0, d) d = d - 2 b = b - 2 time.sleep(0.005) #time.sleep(3) while(a <= 350): pwm.set_pwm(0, 0, a) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) a = a + 2 z = z - 2 g = g - 2 e = e - 2 time.sleep(0.005) while(led >= 0): pwm.set_pwm(12, 0, led) pwm.set_pwm(13, 0, led) led = led - 15 time.sleep(0.01) led = led + 15 def bk(): global a, b, c, d, e, z, g, h, i, j, k, l, text, led name = "gTTS_Text2Speech" text = "はい" language = "ja" text_to_speech(text, language, name) pygame.mixer.music.load("gTTS_Text2Speech.mp3") pygame.mixer.music.play(0) while(led <= 4095): pwm.set_pwm(12, 0, led) pwm.set_pwm(13, 0, led) led = led + 15 time.sleep(0.01) led = led - 15 while True: if(pygame.mixer.music.get_busy()!=True): break time.sleep(0.2) pygame.mixer.music.stop() time.sleep(1) text = "" while(d >= 305): pwm.set_pwm(1, 0, b) pwm.set_pwm(3, 0, d) d = d - 2 b = b - 2 time.sleep(0.005) #time.sleep(3) while(c >= 330): pwm.set_pwm(2, 0, c) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) c = c - 2 z = z + 2 g = g + 2 e = e + 2 time.sleep(0.005) #time.sleep(3) while(b <= 320): pwm.set_pwm(1, 0, b) pwm.set_pwm(3, 0, d) d = d + 2 b = b + 2 time.sleep(0.005) #time.sleep(3) while(c <= 400): pwm.set_pwm(2, 0, c) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) c = c + 2 z = z - 2 g = g - 2 e = e - 2 time.sleep(0.005) #time.sleep(3) while(b <= 380): pwm.set_pwm(1, 0, b) pwm.set_pwm(3, 0, d) b = b + 2 d = d + 2 time.sleep(0.005) #time.sleep(3) while(a <= 420): pwm.set_pwm(0, 0, a) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) a = a + 2 z = z - 2 g = g - 2 e = e - 2 time.sleep(0.005) #time.sleep(3) while(b >= 320): pwm.set_pwm(1, 0, b) pwm.set_pwm(3, 0, d) d = d - 2 b = b - 2 time.sleep(0.005) #time.sleep(3) while(a >= 350): pwm.set_pwm(0, 0, a) pwm.set_pwm(4, 0, e) pwm.set_pwm(5, 0, z) pwm.set_pwm(6, 0, g) a = a - 2 z = z + 2 g = g + 2 e = e + 2 time.sleep(0.005) while(led >= 0): pwm.set_pwm(12, 0, led) pwm.set_pwm(13, 0, led) led = led - 15 time.sleep(0.01) led = led + 15 while True: try: block = stream.read(chunk, exception_on_overflow=False) amplitude = get_rms(block) if not is_recording: if amplitude > THRESHOLD: is_recording = True print("Recording started") frames = [] elif is_recording: if amplitude > THRESHOLD: silence_counter = 0 # Record audio block frames.append(block) type = "on" print("rokuon") else: if type == "on": #print("on") cdown = time.time() #for i in range(0, int(RATE / chunk * RECORD_SECONDS)): while True: if time.time() < cdown + 3 and amplitude < THRESHOLD: #data = stream.read(block) block = stream.read(chunk, exception_on_overflow=False) frames.append(block) #t_end = time.time() #t_time = 3 #if time.time() < t_end + t_time: #frames.append(block) #print("kuuhaku") else: print("aaaaaaaaaaaaaaaaaaaaaaaaaaaaa") break #time.sleep(3) type = "off" silence_counter += 1 if silence_counter > (RATE / chunk) * SILENCE_LIMIT: is_recording = False silence_counter = 0 print("Recording stopped") # Save recorded audio to file wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') wf.setnchannels(CHANNELS) wf.setsampwidth(p.get_sample_size(FORMAT)) wf.setframerate(RATE) #print(frames) #frames = [struct.pack('h', s) for s in frames] wf.writeframes(b''.join(frames)) wf.close() frames = [] #print("nnnnnnnnnnnnaaaaaaaaaaaaaaaaaaasssssssssssssiiiiiiiiii") # 音声ファイルを読み込む with wave.open("output.wav", "rb") as f: frames = f.readframes(f.getnframes()) sample_rate = f.getframerate() sample_width = f.getsampwidth() channels = f.getnchannels() print("wait....") msg = 1 ### rb(read binary)でデータを読み込む with io.open(speech_file, 'rb') as f: content = f.read() ### RecognitionAudioにデータを渡す audio = speech.RecognitionAudio(content=content) config = speech.RecognitionConfig( ### encodeでエラーが出たのでENCODING_UNSPECIFIEDに変更 encoding=speech.RecognitionConfig.AudioEncoding.ENCODING_UNSPECIFIED, sample_rate_hertz=44100, language_code="ja-JP", ) ### 音声を抽出 response = client.recognize(config=config, audio=audio) ### 抽出結果をprintで表示 for result in response.results: if "{}".format(result.alternatives[0].transcript) == "": text = "" frames = [] break print("Transcript: {}".format(result.alternatives[0].transcript)) text = "{}".format(result.alternatives[0].transcript) # ChatGPTにテキストを送信して回答を受け取る if text != "": if text == "こんにちは": power() elif text == "前に歩いて": fw() elif text == "後ろに歩いて": bk() else: th = threading.Thread(target=recieve) th.start() messages = [ {"role": "system", "content"}, {"role": "user", "content": text} # ---(※5) ] response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=messages) print("response" + response.choices[0]["message"]["content"].strip()) text = response.choices[0]["message"]["content"].strip() msg = 2 #ChatGPTの回答を音声データに変換してファイルに保存する language = "ja" # 保存ファイル名 name = "gTTS_Text2Speech" # 関数実行 text_to_speech(text, language, name) # 音楽ファイルの読み込み pygame.mixer.music.load("gTTS_Text2Speech.mp3") # 音楽再生 pygame.mixer.music.play(0) while True: if(pygame.mixer.music.get_busy()!=True): break time.sleep(0.2) pygame.mixer.music.stop() text = "" print("Done.") msg = 3 th = threading.Thread(target=recieve2) th.start() except KeyboardInterrupt: break GPIO.cleanup() stream.stop_stream() p.terminate() |
こだわったポイント
・ロボットの電源ON,OFFをタクトスイッチ制御
・電源投入時にWEBサーバー、カメラストリーミング、AI会話プログラム、アナログコントローラープログラムを自動で起動
・音声でのロボット操作
タクトスイッチでの電源ON,OFFは /boot/config.txt に以下のコマンドを追加すればOKです。
dtoverlay=gpio-shutdown,gpio_pin=26,debounce=2000
pinは通常3を利用するそうですが、i2c使用時は使えないので、その場合は以下のコメントアウトを外すと違うピン番号を使う事が出来ます。
#dtparam=i2c_arm=on
最後の数字は2秒になります。スイッチを押して2秒後にシャットダウンになります。これはスイッチのエッジ検出を防ぐ為に秒数を設けています。
カメラストリーミングは起動のシェルスクリプトを作成し、/etc/rc.loal にパスを追加。
コントローラーのプログラムもパスを追加することで起動時にプログラムが走ります。
AI会話プログラムのみ、後述していますがrc.localにパスを追加してもダメでしたので、ターミナルを起動してプログラムを実行する方法にしました。
音声でのロボット操作は、指定したメッセージをmicから拾えば、chatgptにテキストを投げずにそのままサーボ駆動させています。
ハマったポイント
・mjpgstreamerがbullseyeに対応していない(Busterまで)
・WM8960のドライバが bullseye 以降しか対応していない
・ AI会話プログラム の自動起動が上手く行かない
・pythonプログラムのgpioセットアップ時、 WM8960 がエラーを吐く
カメラのストリーミングについては、個人的に使い勝手のいいmjpgstreamerを使用していたのですが、これが旧OSしか対応しておらず、また WM8960のドライバが bullseye 以降しか対応していなかったので先ずここでつまづきました。
パワー君が旧OS( Buster )で作成していたので、出来れば旧OSで進めたかったのですが、どうあがいてもWM8960の旧バージョン対応化が無理そうでしたので bullseye で進める事にしました。
色々さがしていると、下記サイトにて bullseye でのmjpgstreamerの起動方法が書いていましたので利用させて頂きました。↓
続いて、AI会話プログラムの自動起動ですが、電源投入時のプログラム自動起動はrc.localにプログラム名を追加するなど色々あるのですが、上手く行きませんでした。
そこで見つけたのが、「ターミナルを自動起動してからのプログラム実行」でした。この方法だと上手く起動してくれました。参考にしたサイトはこちら↓
https://qiita.com/tonosamart/items/f59daa481f90c85a8a99
最後に、AI会話プログラム実行後に WM8960 関係のエラーについてです。
エラー内容が音声関係だったのですが、色々原因を探っていくとgpioが起因している事がわかりました。
どうやらいくつかのgpioピン(i2c,spi以外のピン)もWM8960の制御に関わっているらしく、例えばgpio19を使おうとすると音声関係のエラーが出ます。この辺りは恐らく WM8960 のデータシートを見ると分かると思いますが、とりあえずgpio6,gpio13など使えば問題はありませんでした。